
Text-to-Image generation is a subset of Generative Adversarial Networks (GANs), a type of deep learning framework that pits two neural networks against each other in a game-like scenario. One network, the generator, creates new images based on text descriptions, while the other network, the discriminator, assesses the generated images to determine their authenticity. Through this iterative process of creation and evaluation, the generator learns to produce increasingly realistic images that closely match the provided text descriptions.
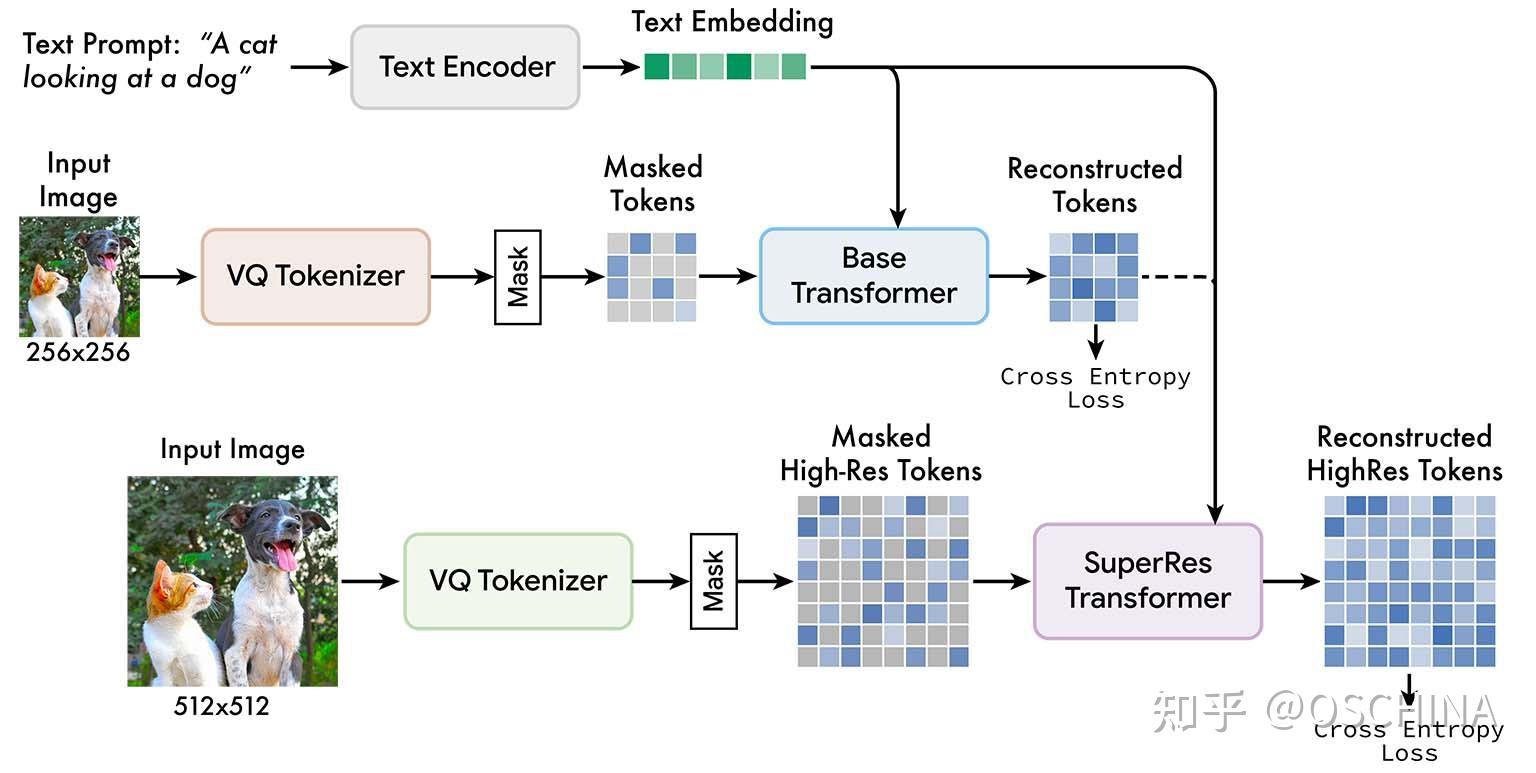
The applications of Text-to-Image generation are vast and varied, spanning across industries such as design, entertainment, and e-commerce. For instance, in the field of graphic design, AI-powered tools can generate visual assets based on textual prompts, streamlining the creative process and enabling designers to explore new concepts and ideas. In the entertainment industry, Text-to-Image generation can be used to create lifelike characters for movies, video games, and virtual reality experiences, enhancing the immersive quality of digital content.

Moreover, in e-commerce, Text-to-Image generation can revolutionize the way products are showcased online. By generating realistic images of products based on textual descriptions, retailers can provide customers with a more engaging and personalized shopping experience, increasing conversion rates and customer satisfaction.

Despite its many advantages, Text-to-Image generation still faces challenges, such as generating high-quality images that accurately reflect the text descriptions and maintaining diversity in the generated content. Researchers and developers are continuously working to overcome these obstacles by refining the underlying algorithms, improving data quality, and exploring new techniques to enhance the performance of Text-to-Image models.
